Apache Spark is a game changer for big data analytics. In many ways, it will democratize analytics on big data. Spark will do this by making big data analytics accessible to a much larger group of data scientists (and analysts) via a simple programming API and familiar tools such as SQL, Python and R. Being open source, it will also allow many companies to embrace it with a smaller initial capital investment. Spark is also being embraced by IBM and other large analytic software providers as the engine that will drive their big data applications. The primary benefits of Spark are the ability to scale analytics to massive data sets and that Spark is a significantly easier to use platform (than Hadoop + Map Reduce + custom code) that will allow data scientists to be far more productive. Rapid development often results in a faster ROI.
Let’s define some technologies that are part of the big data/Spark ecosystem.
Hadoop – Hadoop is an ecosystem of open source software products that enable massive amounts of data to be split up and stored across clusters of low-cost commodity servers (usually running Linux). Hadoop allows for efficient and scalable storage of data by splitting the data across multiple servers. Map Reduce jobs can be written (typically in Java) to access the data and reduce it into a single data set for analysis. The base layer of Hadoop is HDFS. It’s a distributed (across many servers) file system that allows data to be stored as if it were a single, simple file system (with folders and files). Files are typically stored in Avro format or plain old CSV (comma separated values). Hive is a Hadoop technology that allows the data in HDFS to be accessed by SQL (structured query language).
Spark – Spark is a platform for big data analytics that typically sits on top of Hadoop. Spark improves on Hadoop in many ways (in addition to adding new functionality).
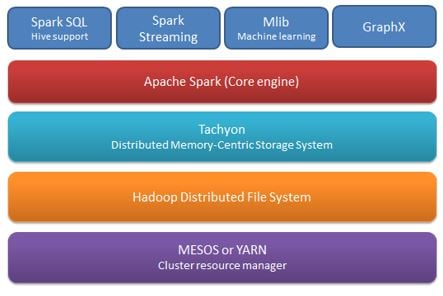
Spark SQL leverages and enhances Hive to allow data in Hadoop to be accessed via SQL. Spark Streaming allows data scientist to process and analyze streaming data as if it were a batch process. MLLib is a powerful machine-learning library that allows data scientists to scale algorithms such as RandomForest to massive data sets by leveraging the power of multiple commodity servers (similar to how Hadoop leverages clusters of servers). Whereas Hadoop requires Map Reduce jobs, that store intermediate data to disk, Spark does it’s work in memory allowing it to perform many tasks orders of magnitudes faster than using Map Reduce and traditional algorithmic approaches such Python and R alone.
When to use Hadoop
First, it’s important to understand that Hadoop is not a replacement for traditional databases (RDBMS). It’s not well suited to transactional systems or other systems that require frequent updates. Hadoop is a platform that steps in when traditional RDBMS’s fail because of the sheer amount of data to be stored/analyzed or because you are storing a large amount of unstructured data (data that cannot be put into rows/columns easily). If you are throwing away data you collect because it isn’t practical to store, but you feel this data may someday have a use, Hadoop is a good alternative to a traditional RDBMS.
A more detailed analysis of when to use Hadoop can be found at: http://www.datanami.com/2014/01/27/when_to_hadoop_and_when_not_to/
When to use Spark
Spark = efficient access to big data in memory + HPC (high performance computing)
Case 1: You need big data analytics
If you need to analyze billions of customer transactions (or website clicks) to build a recommendation engine, Spark will allow you to manage the massive amounts of data and build association models leveraging the parallel processing power of the entire Spark cluster. The more (cheap commodity) servers you throw at Spark the faster your analyses will be.
Case 2: Your analytics process is complex and requires many iterations
If you are performing risk analytics and need to build hundreds of predictive models and score those models using Monte Carlo simulation, you may not have billions of rows but you are going to clobber the CPU on a single machine and running the simulations/modeling building serially will require days of processing time. Spark can split this work up across the Spark cluster and perform the task orders of magnitude faster.
Big Data use cases
In addition to risk analytics and recommendation engines, there are some additional compelling use cases. To learn more check out this article: https://www.mapr.com/solutions/enterprise-big-data-and-hadoop-use-cases.
Remember, that throwing away data now because you are not sure how you will use it is a mistake you cannot fix in the future. Once the data is gone, it’s gone. What will your future use cases be? If there’s no data, you are out of luck.
Final thoughts
As a data scientist, I regularly run into cases where clients throw away massive amounts of data because storing and analyzing this data was previously impractical. It’s often been said that a company’s data is their greatest corporate asset. If that’s true, why throw away what could be a competitive differentiator in the near future. It’s time to think about keeping that data in Hadoop and analyzing it in Spark!